Equivariant Q Learning in Spatial Action Spaces
Abstract: Recently, a variety of new equivariant neural network model architectures have been proposed that generalize better over rotational and reflectional symmetries than standard models. These models are relevant to robotics because many robotics problems can be expressed in a rotationally symmetric way. This paper focuses on equivariance over a visual state space and a spatial action space – the setting where the robot action space includes a subset of SE(2). In this situation, we know a priori that rotations and translations in the state image should result in the same rotations and translations in the spatial action dimensions of the optimal policy. Therefore, we can use equivariant model architectures to make Q learning more sample efficient. This paper identifies when the optimal Q function is equivariant and proposes Q network architectures for this setting. We show experimentally that this approach outperforms standard methods in a set of challenging manipulation problems.
Paper
Published at the Conference on Robot Learning (CoRL) 2021
OpenReview
arXiv
Dian Wang, Robin Walters, Xupeng Zhu, Robert Platt
Khoury College of Computer Sciences
Northeastern University
Idea

Robotic manipulation naturally has some equivariant properties. In this block picking example, when the scene is applied with an SE(2) transformation (e.g., rotate by 90 degrees), the optimal policy should also be applied with the same transformation. This work utilizes such equivariant property to accelerate Q learning.
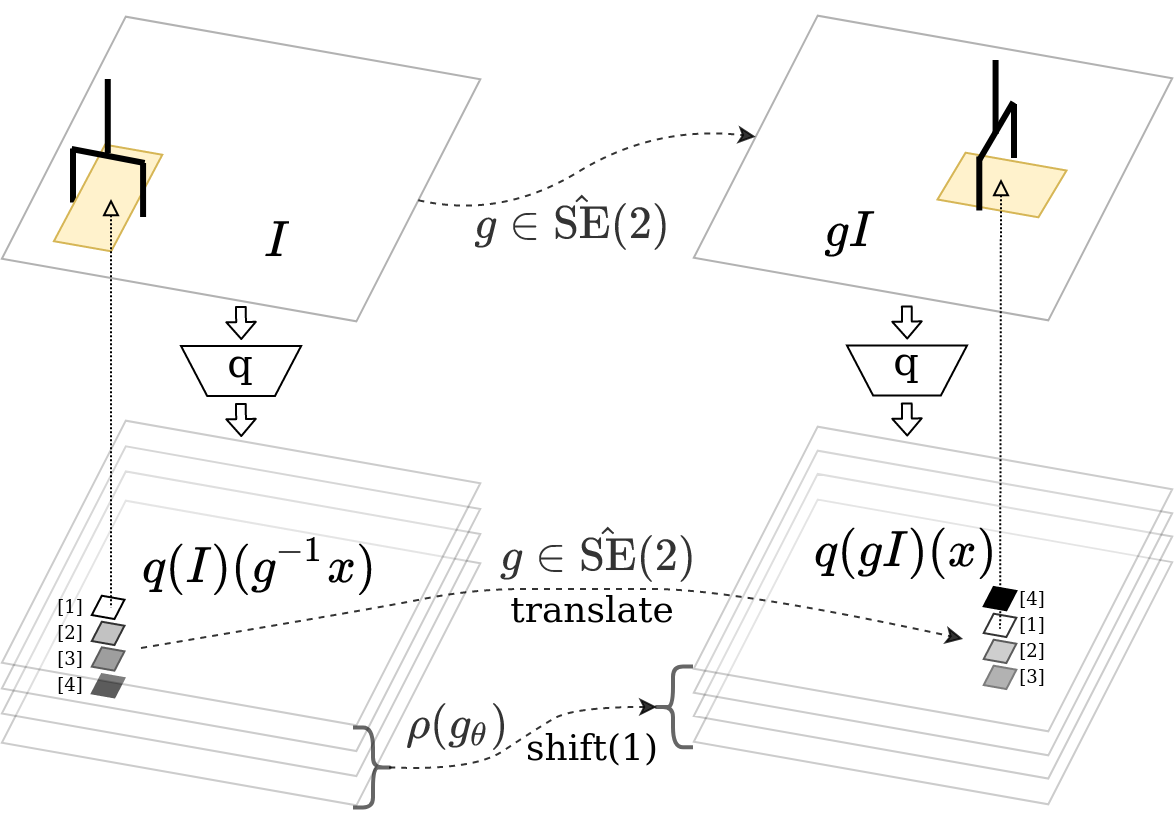
Specifically, in the case of DQN where the input is the manipulation scene and the output is the Q values of all actions, when the scene transforms, the Q map containing the value of all translational actions should also transform; the Q vector containing the value of all rotational actions should circularly permute. By enforcing such equivariant property, our method can solve challanging manipulation tasks much faster than competing baselines.

The Experimental Environments
The manipulation tasks of our experiments. The left subfigure shows the initial state and the right subfigure shows the goal state.
Block Stacking
Bottle Arrangement
House Building
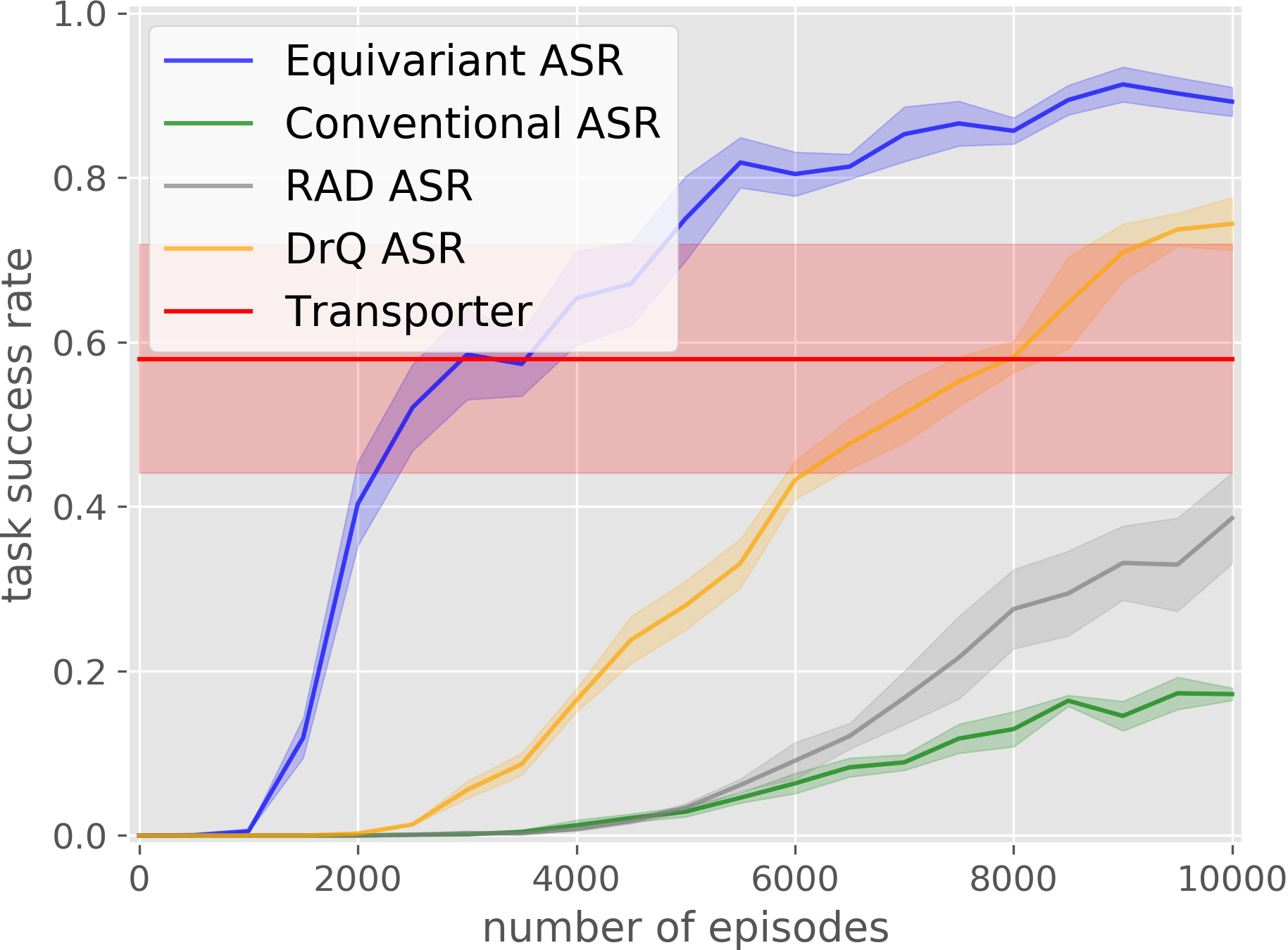
Covid Test
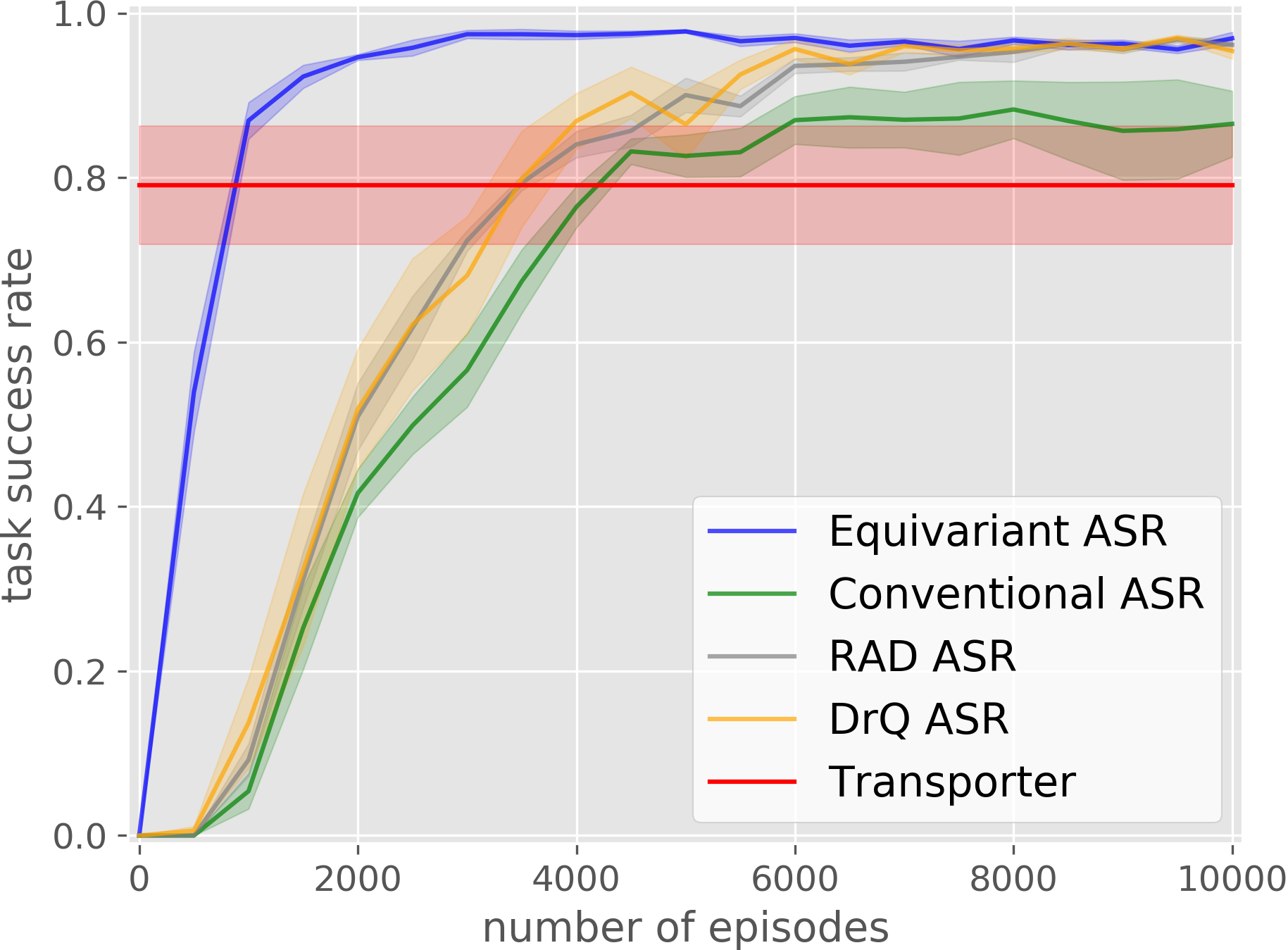
Box Palletizing
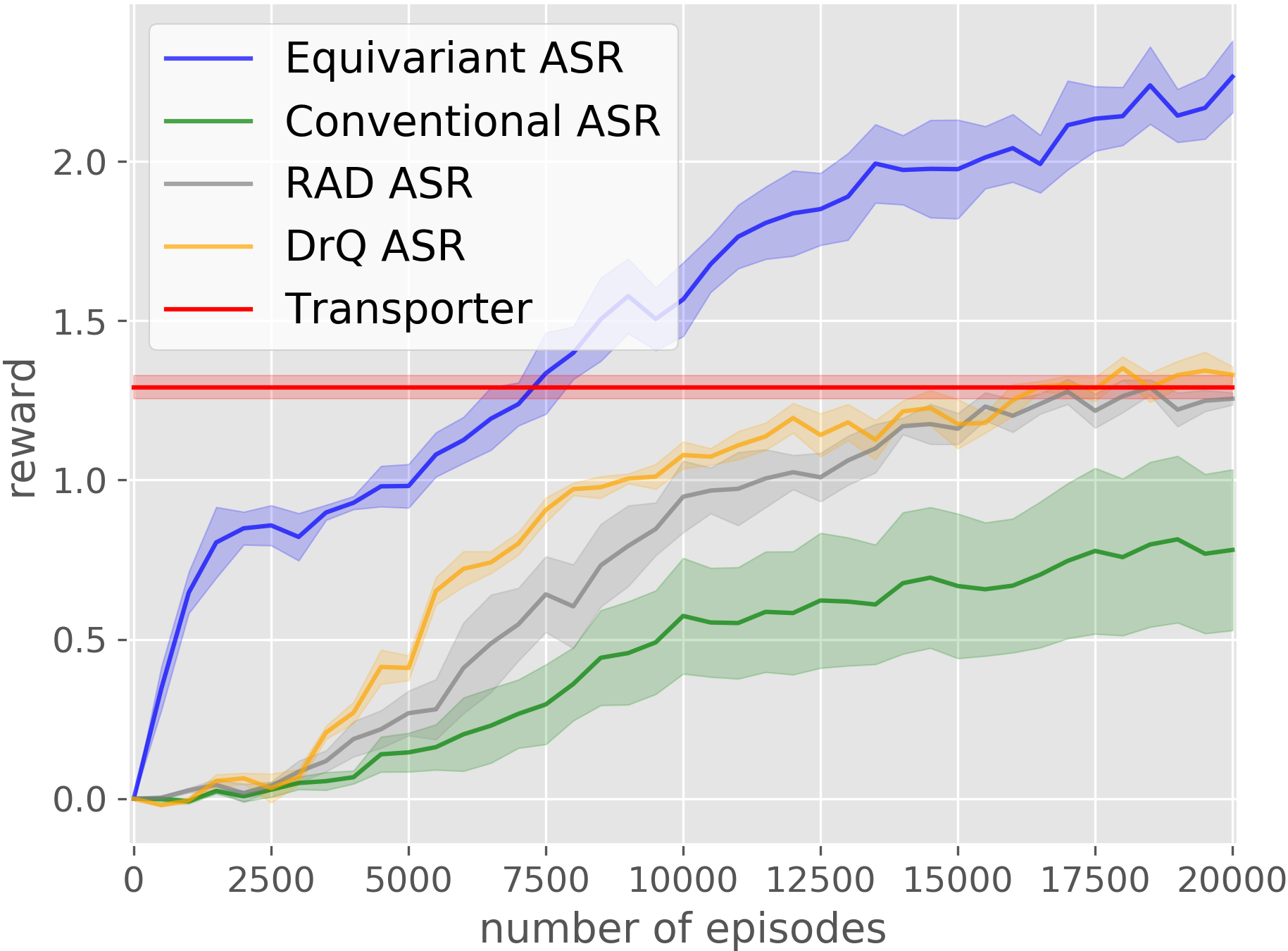
Bin Packing
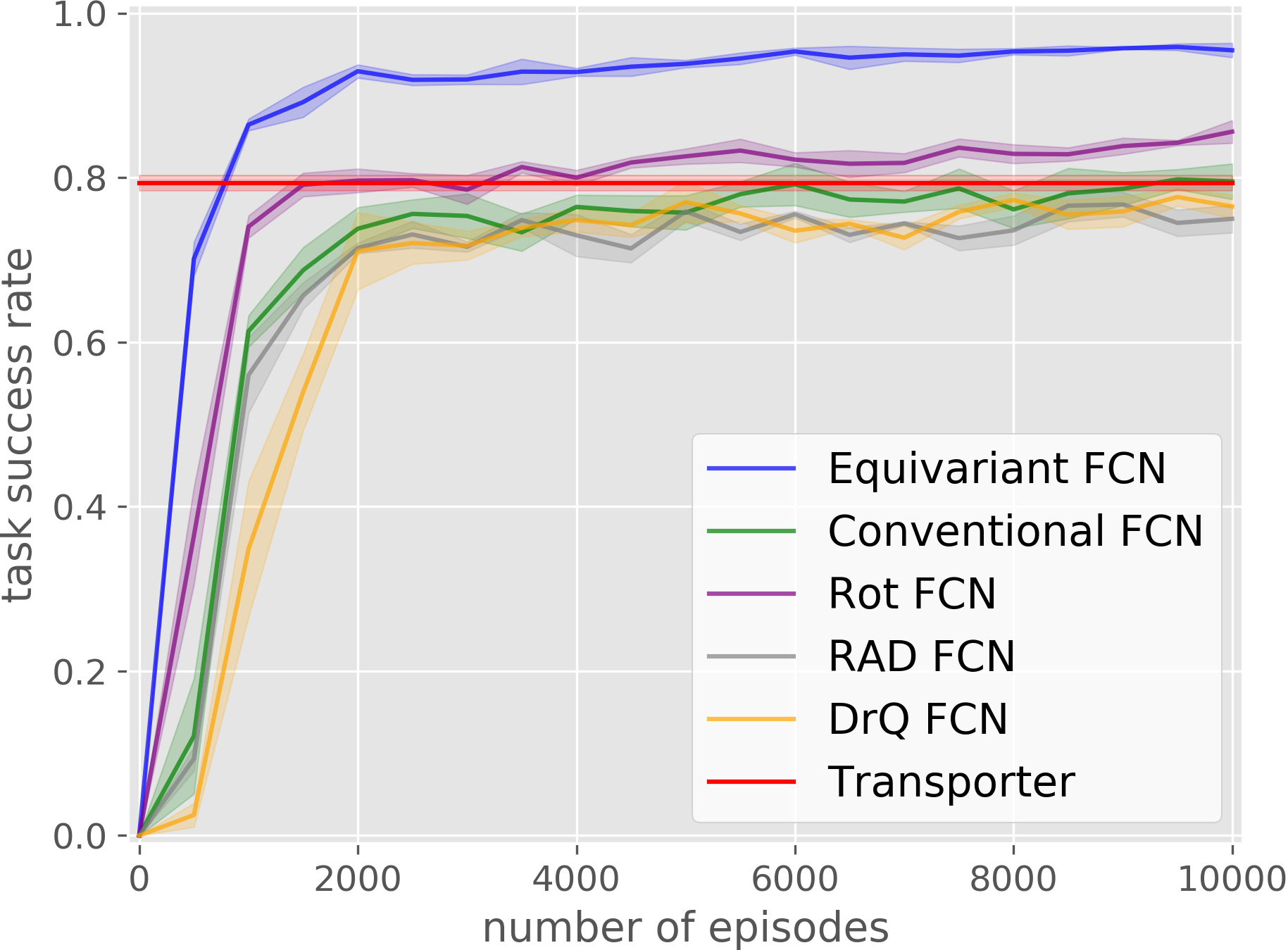
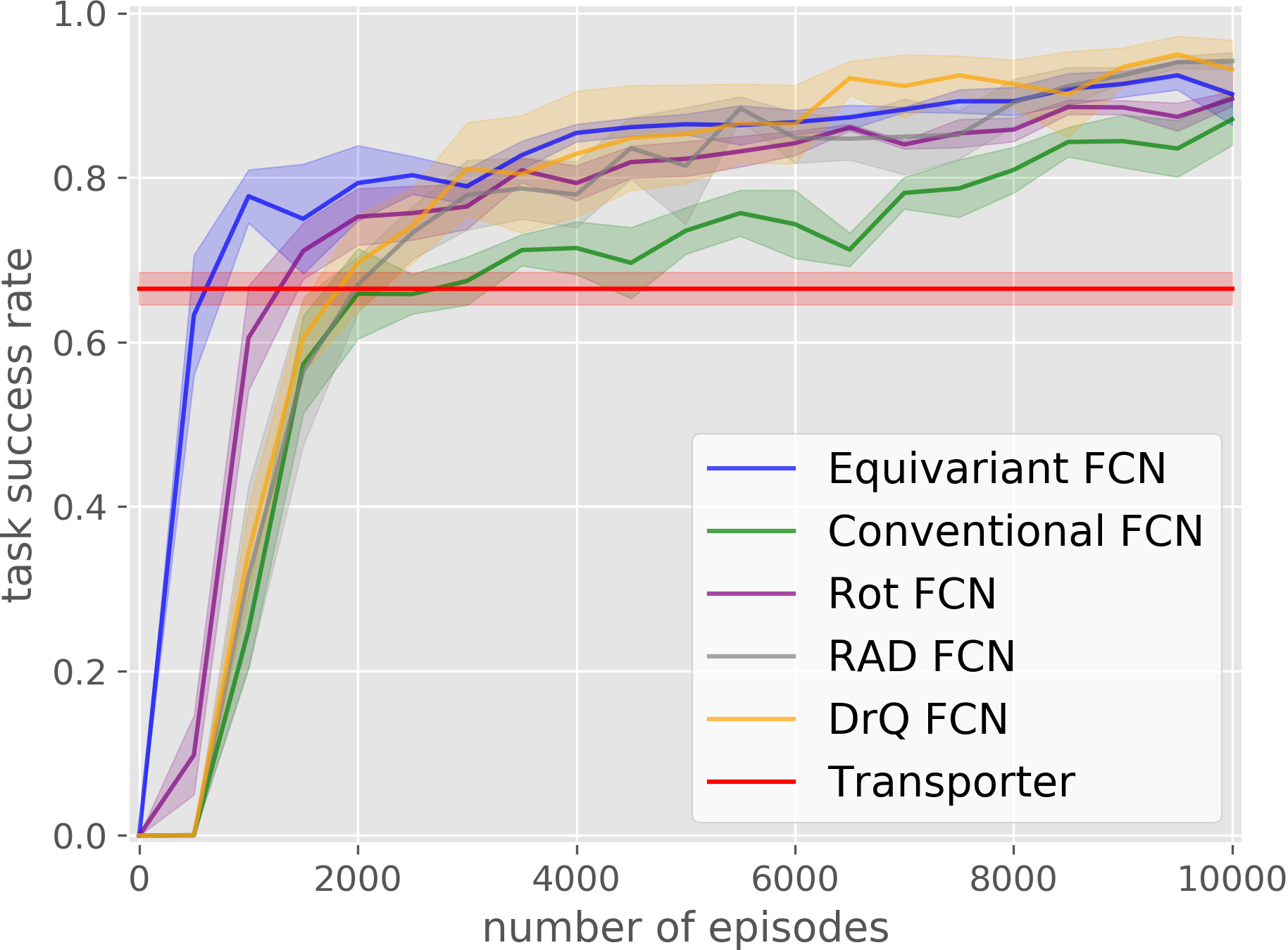
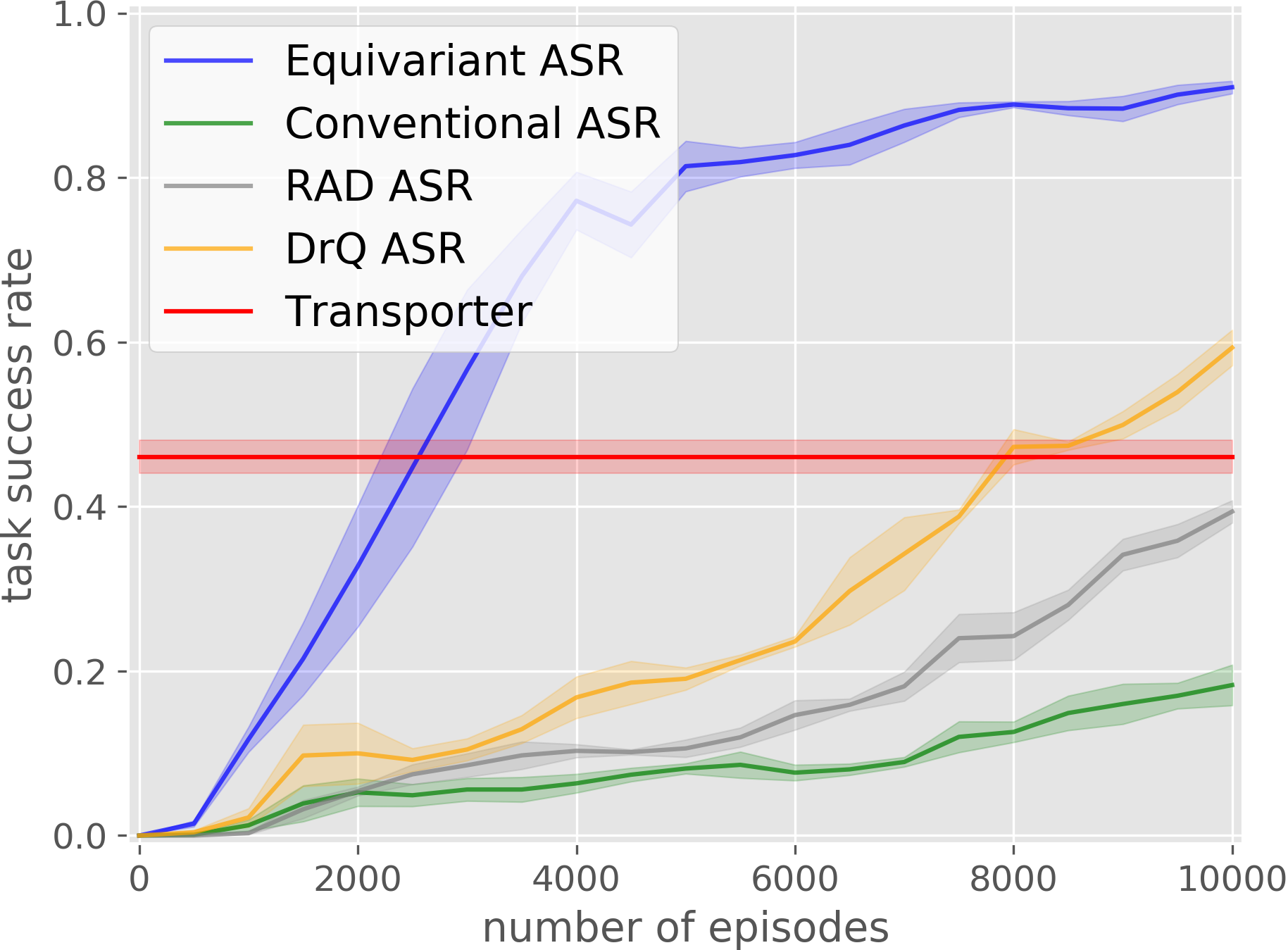
Our equivariant method (in blue) significantly outperforms the baselines in most experiments.

Bottle Arrangement

House Building

Box Palletizing
Our trained model can be applied in the real world.
Video
Code
https://github.com/pointW/equi_q_corl21
Citation
@inproceedings{
wang2021equivariant,
title={Equivariant \$Q\$ Learning in Spatial Action Spaces},
author={Dian Wang and Robin Walters and Xupeng Zhu and Robert Platt},
booktitle={5th Annual Conference on Robot Learning },
year={2021},
url={https://openreview.net/forum?id=IScz42A3iCI}
}
Contact
If you have any questions, please feel free to contact Dian Wang at wang[dot]dian[at]northeastern[dot]edu.