SO(2) Equivariant Reinforcement Learning
Abstract: Equivariant neural networks enforce symmetry within the structure of their convolutional layers, resulting in a substantial improvement in sample efficiency when learning an equivariant or invariant function. Such models are applicable to robotic manipulation learning which can often be formulated as a rotationally symmetric problem. This paper studies equivariant model architectures in the context of Q-learning and actor-critic reinforcement learning. We identify equivariant and invariant characteristics of the optimal Q-function and the optimal policy and propose equivariant DQN and SAC algorithms that leverage this structure. We present experiments that demonstrate that our equivariant versions of DQN and SAC can be significantly more sample efficient than competing algorithms on an important class of robotic manipulation problems.
Paper
Published at The Tenth International Conference on Learning Representations (ICLR 2022)
Spotlight Presentation
arXiv
OpenReview



Khoury College of Computer Sciences
Northeastern University
Poster
Idea

This work studies the SO(2) equivariant property of robotic manipulation in the context of reinforcement learning. We use equivariant networks to enforce the equivariance in the structure of the networks to improve the sample efficiency.
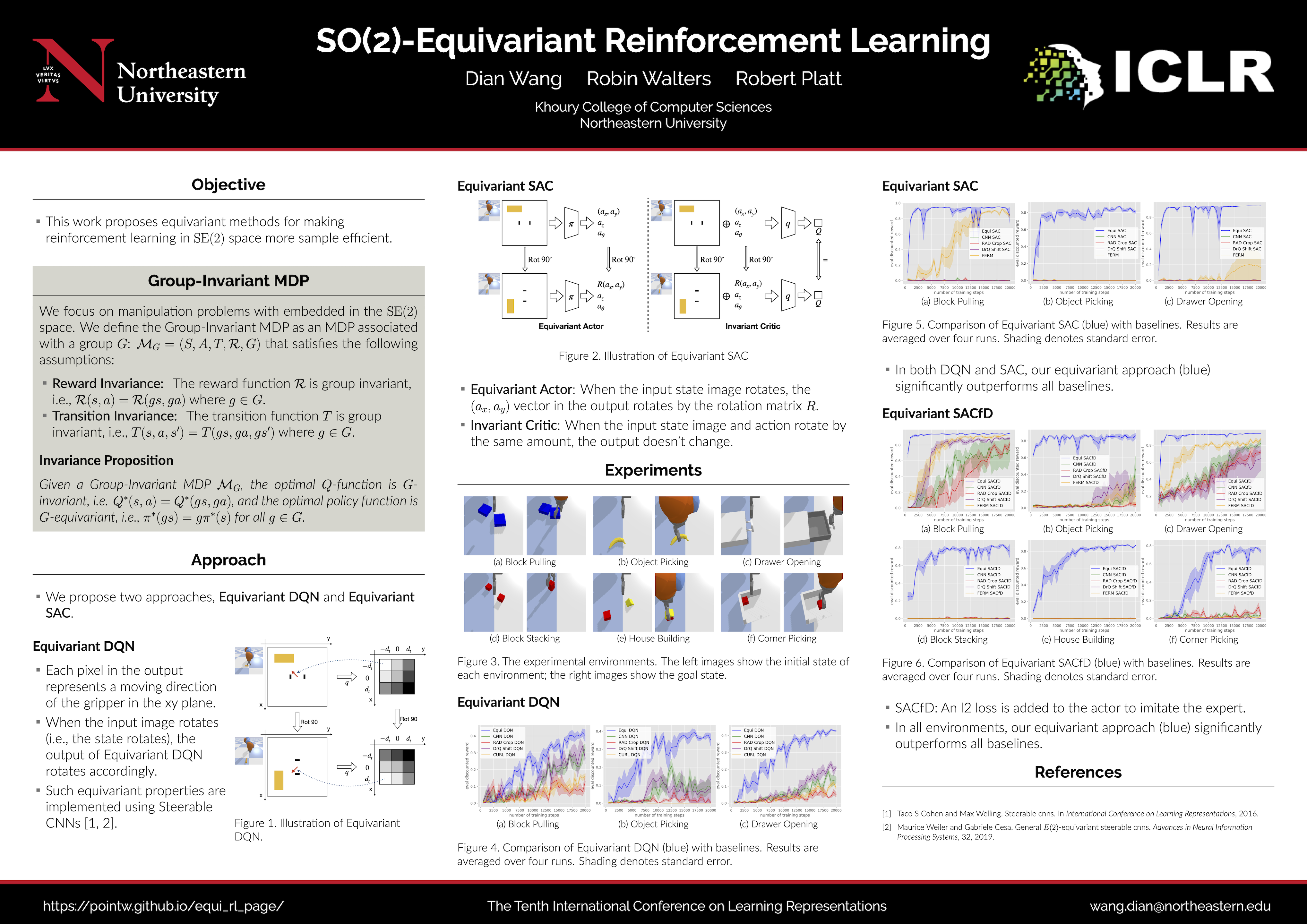
In Equivariant DQN, if the input state of the Q-network is rotated, the output of the Q-network (where the value of each cell in the 3x3 grid represents the Q-value of moving towards a specific direction) will be rotated by the same amount.
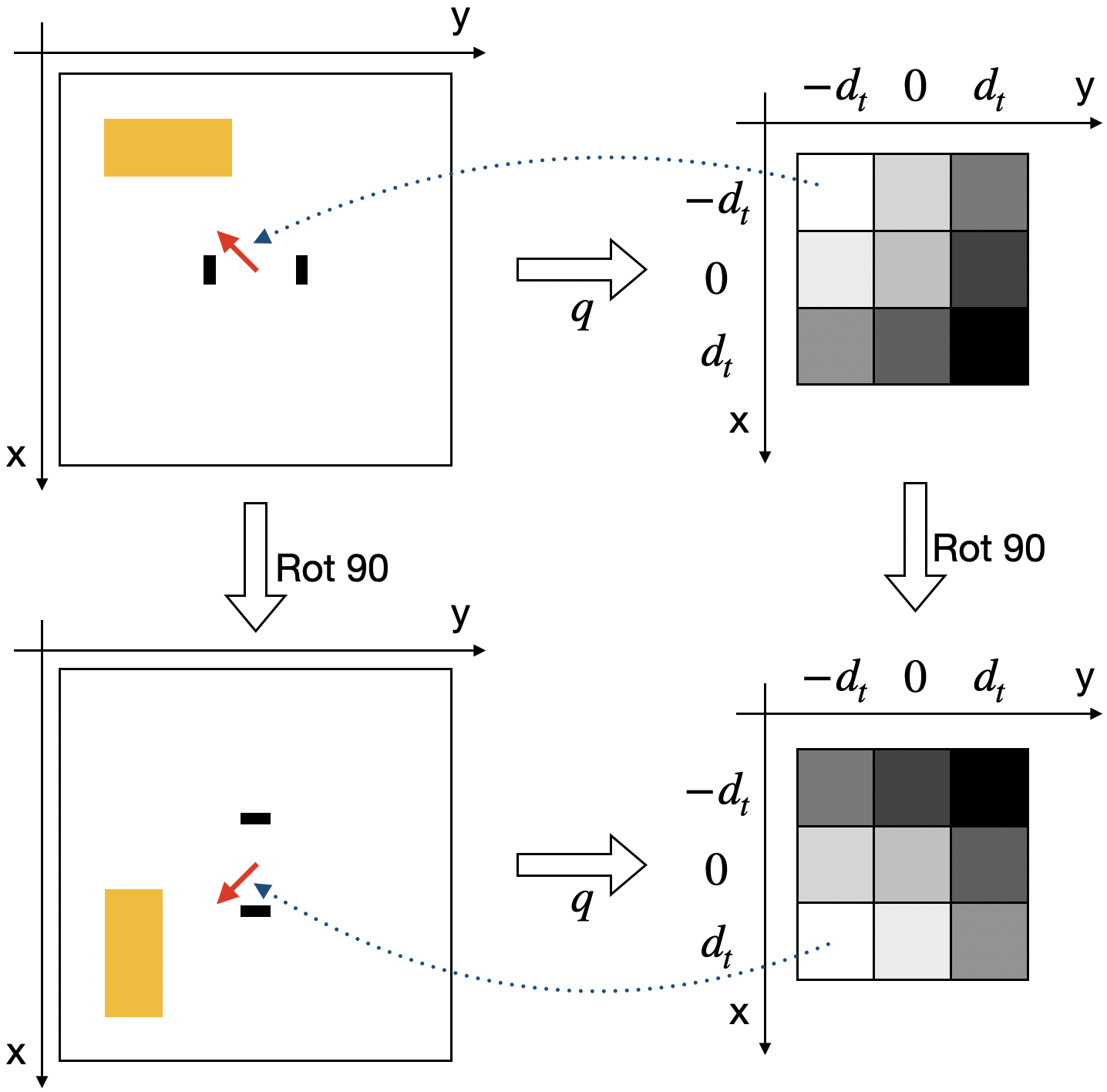
In Equivariant SAC, if the input state of the actor (left) is rotated, the output action of the actor will be rotated by the same amount. If the input state and action of the critic (right) are rotated, the output Q-value of the critic will remain the same.

Object Picking

Block Pulling

Drawer Opening

Block Stacking

House Building

Corner Picking
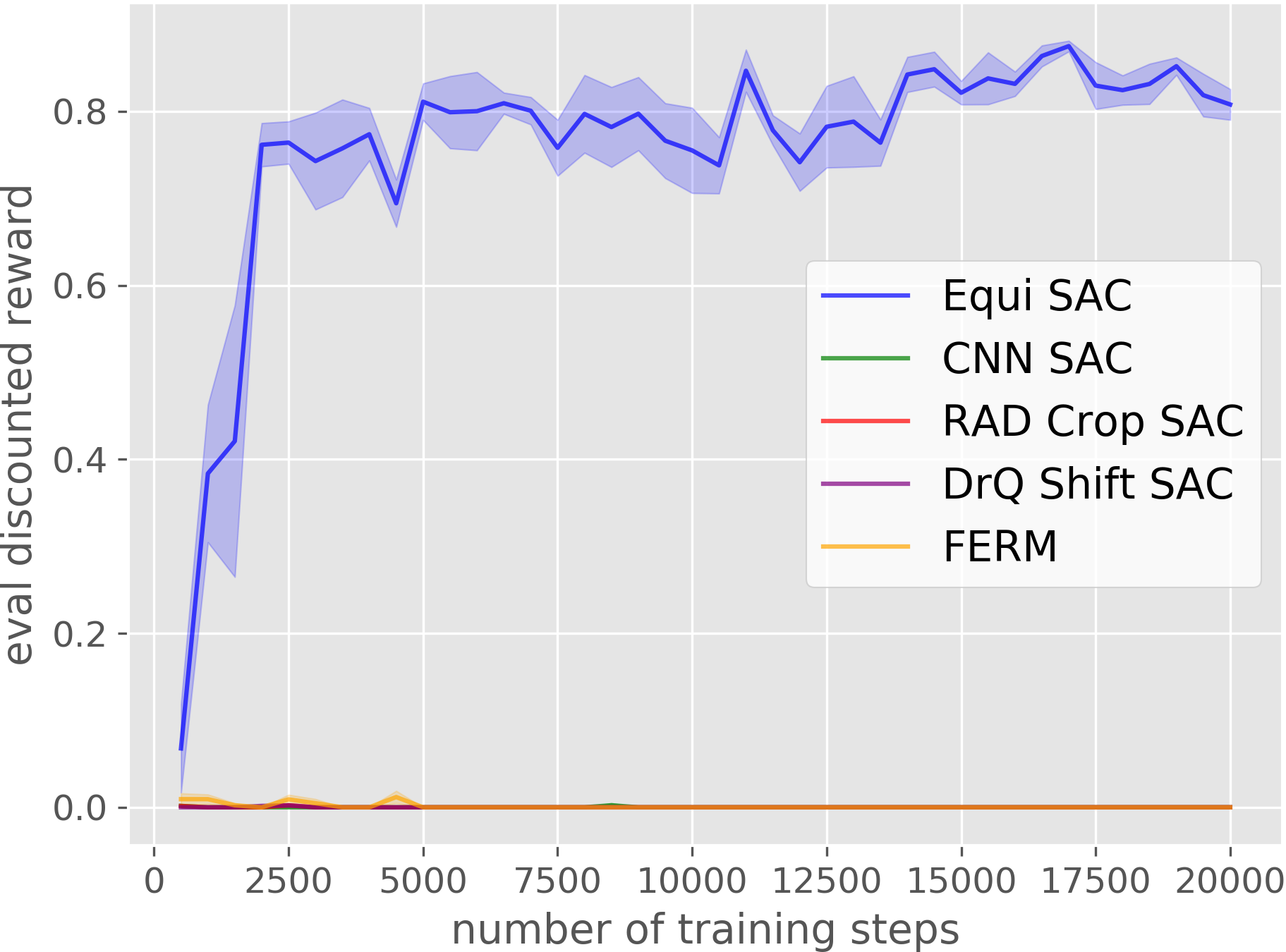
Our Equivariant SAC can solve different manipulation tasks with high sample effeciency.
Object Picking
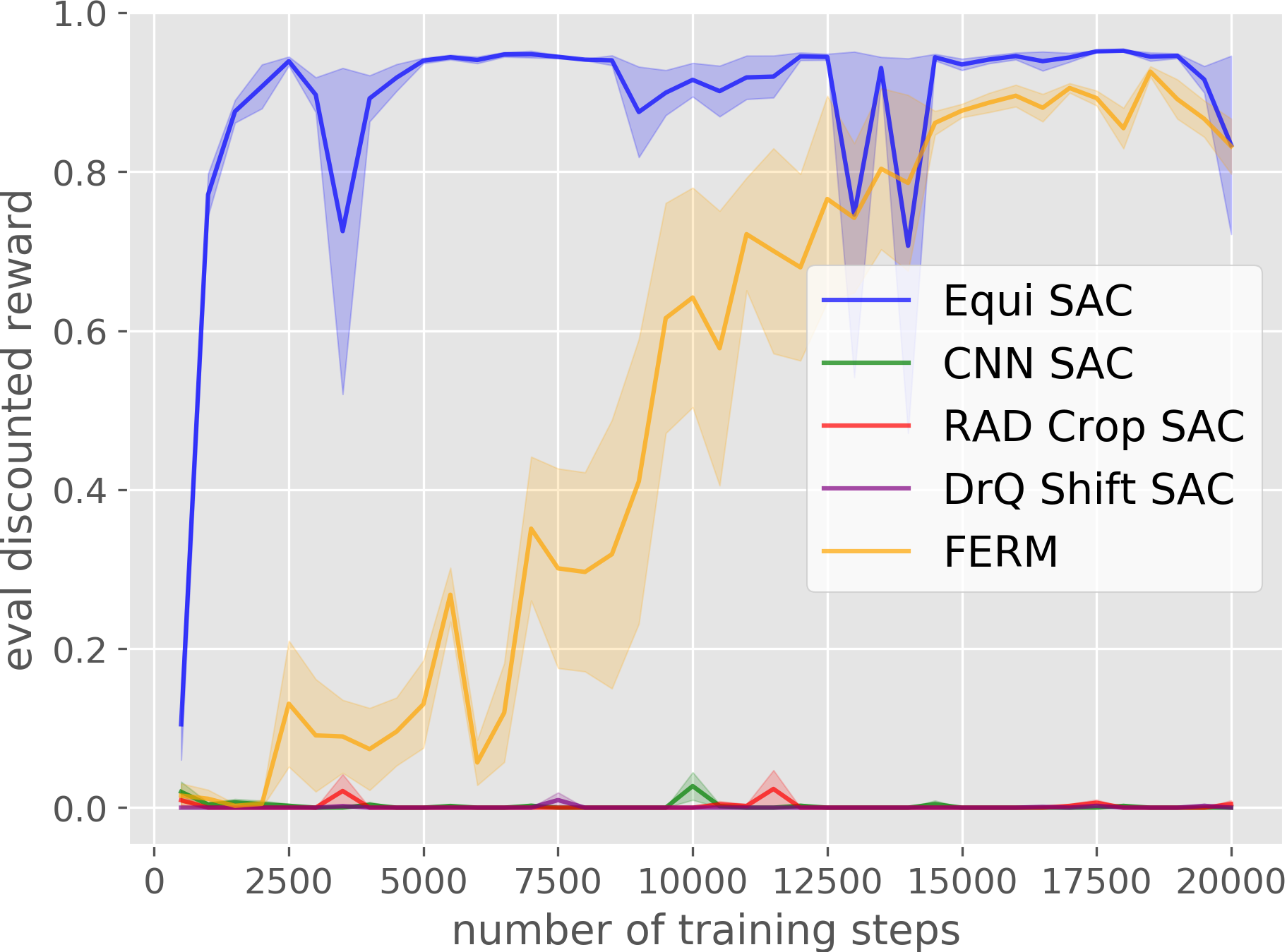
Block Pulling
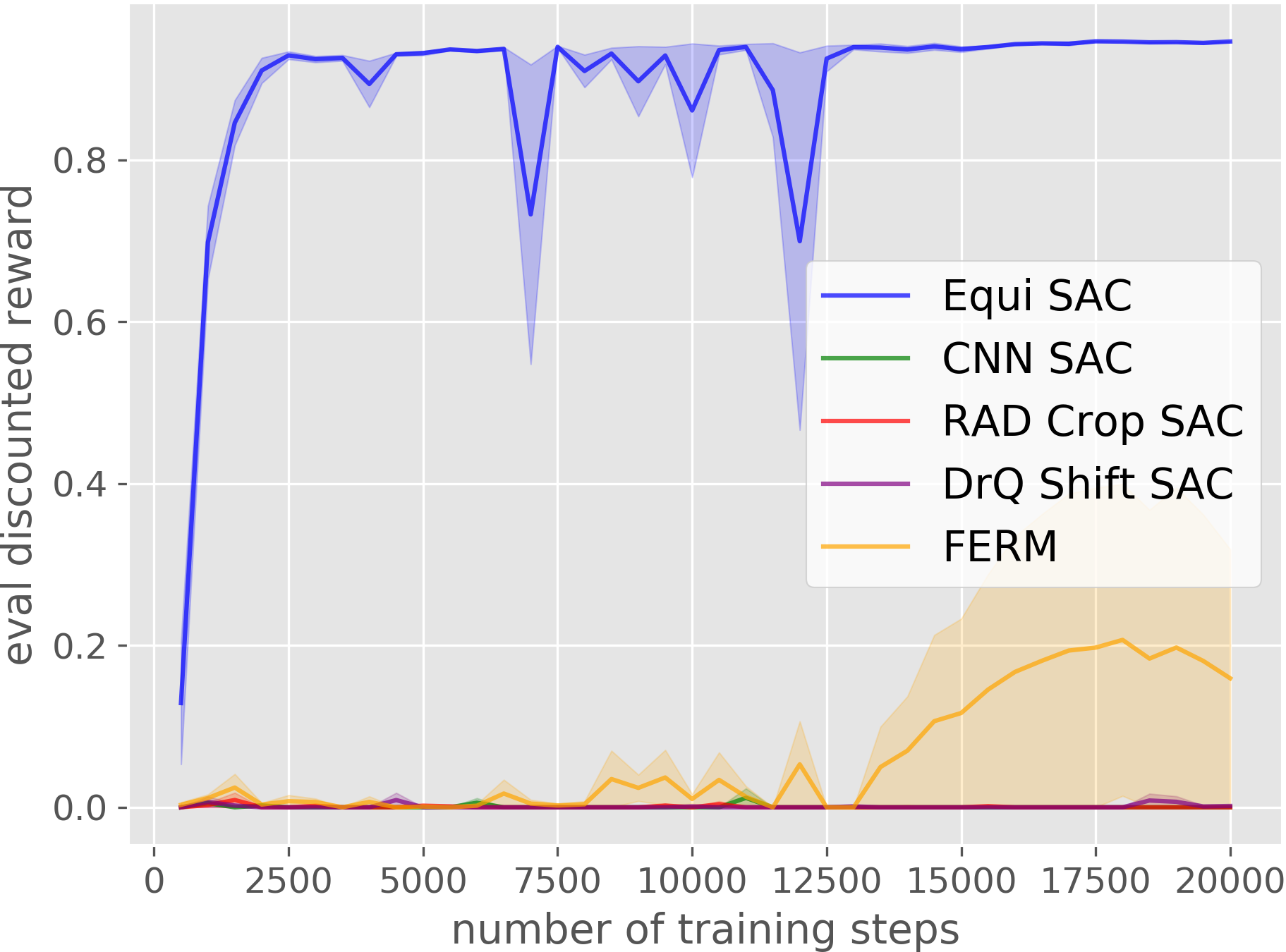
Drawer Opening
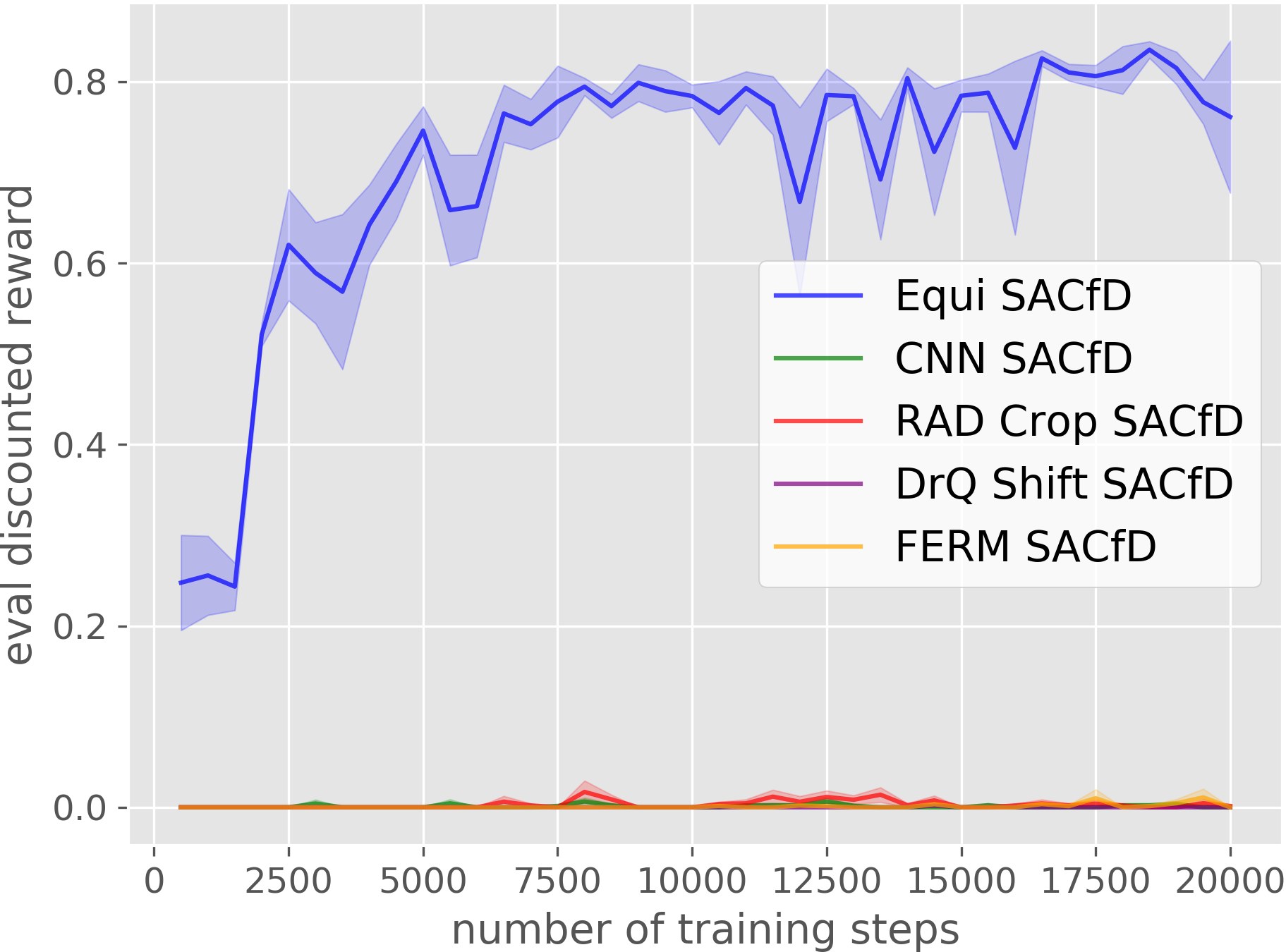
Block Stacking
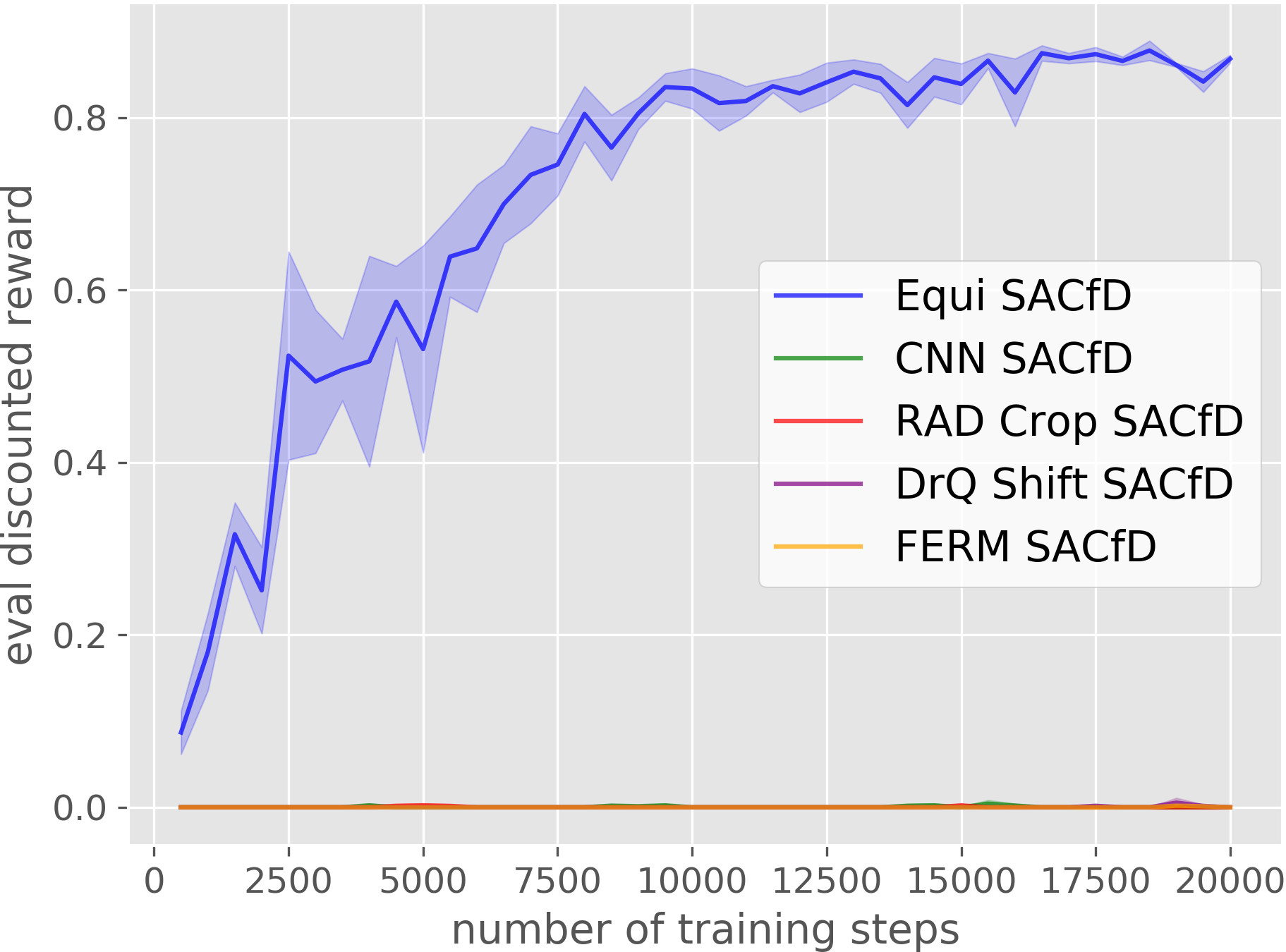
House Building
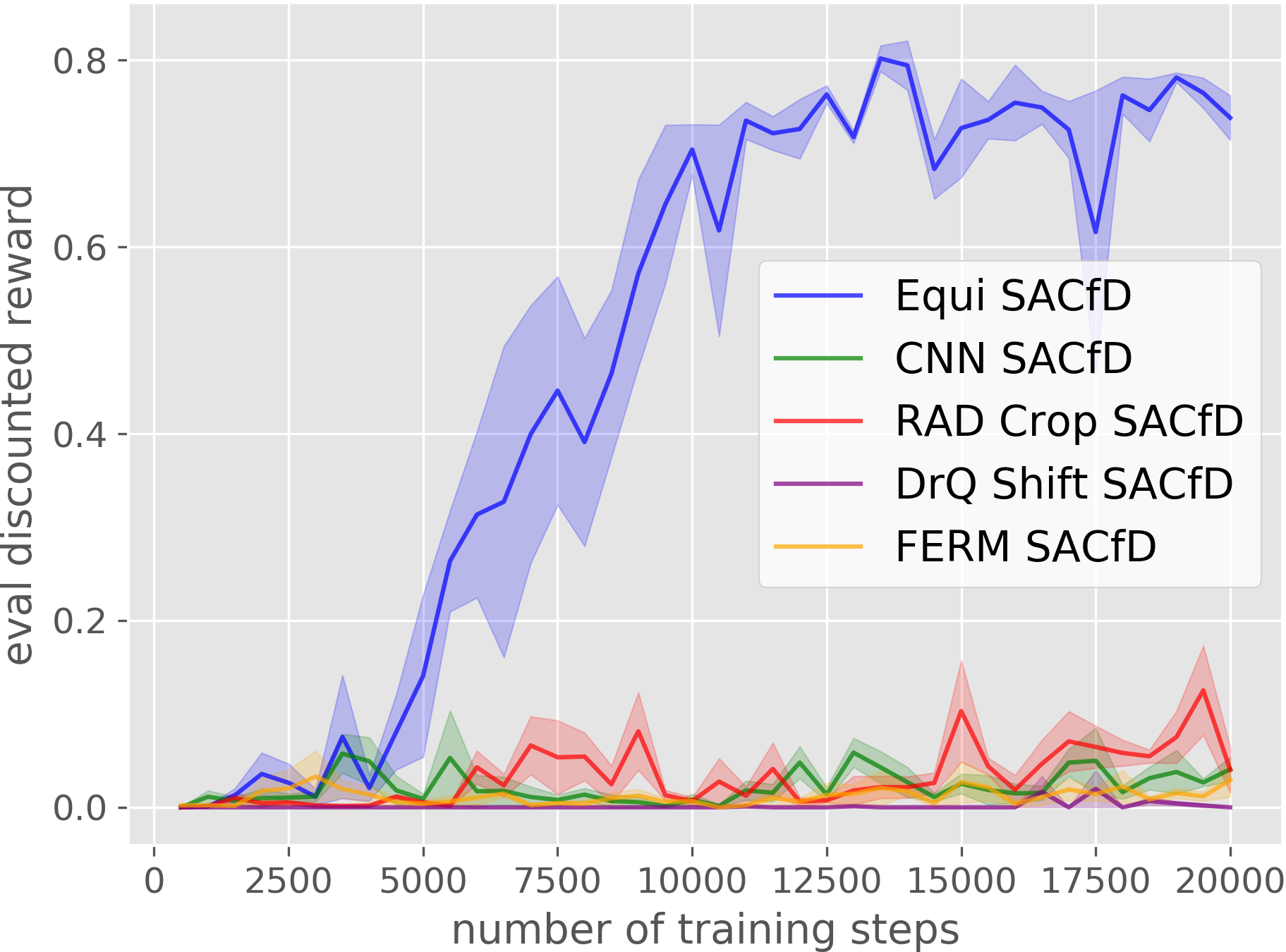
Corner Picking
Our Equivariant method (blue) dramatically outperforms competing baselines, including some sample-efficient baselines using data augmentation.
Video
Code
https://github.com/pointW/equi_rl
Citation
@inproceedings{
wang2022so2equivariant,
title={{$\mathrm{SO}(2)$}-Equivariant Reinforcement Learning},
author={Dian Wang and Robin Walters and Robert Platt},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=7F9cOhdvfk_}
}
Contact
If you have any questions, please feel free to contact Dian Wang at wang[dot]dian[at]northeastern[dot]edu.