On-Robot Learning With Equivariant Models
Abstract: Recently, equivariant neural network models have been shown to im- prove sample efficiency for tasks in computer vision and reinforcement learning. This paper explores this idea in the context of on-robot policy learning in which a policy must be learned entirely on a physical robotic system without reference to a model, a simulator, or an offline dataset. We focus on applications of Equivariant SAC to robotic manipulation and explore a number of variations of the algorithm. Ultimately, we demonstrate the ability to learn several non-trivial manipulation tasks completely through on-robot experiences in less than an hour or two of wall clock time.
Paper
Published at The 6th Annual Conference on Robot Learning (CoRL 2022)
arXiv





Khoury College of Computer Sciences
Northeastern University
Idea
We implement sample-efficient on-robot learning using Equivariant SAC.
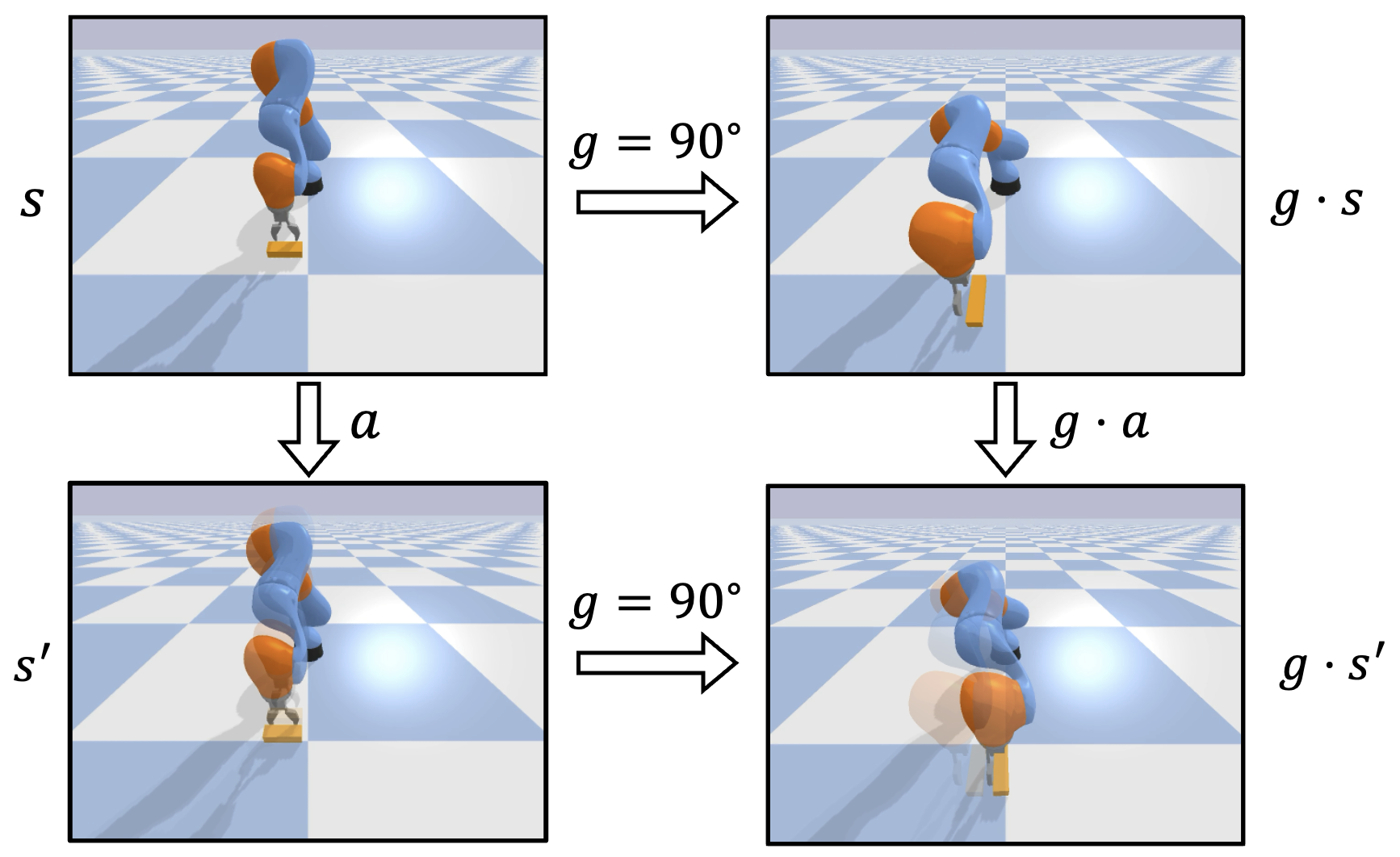
Many robotic manipulation tasks have spatial symmetries. In the block pushing example, rotating the state and the action simultaneously will not change the outcome of the pushing action.
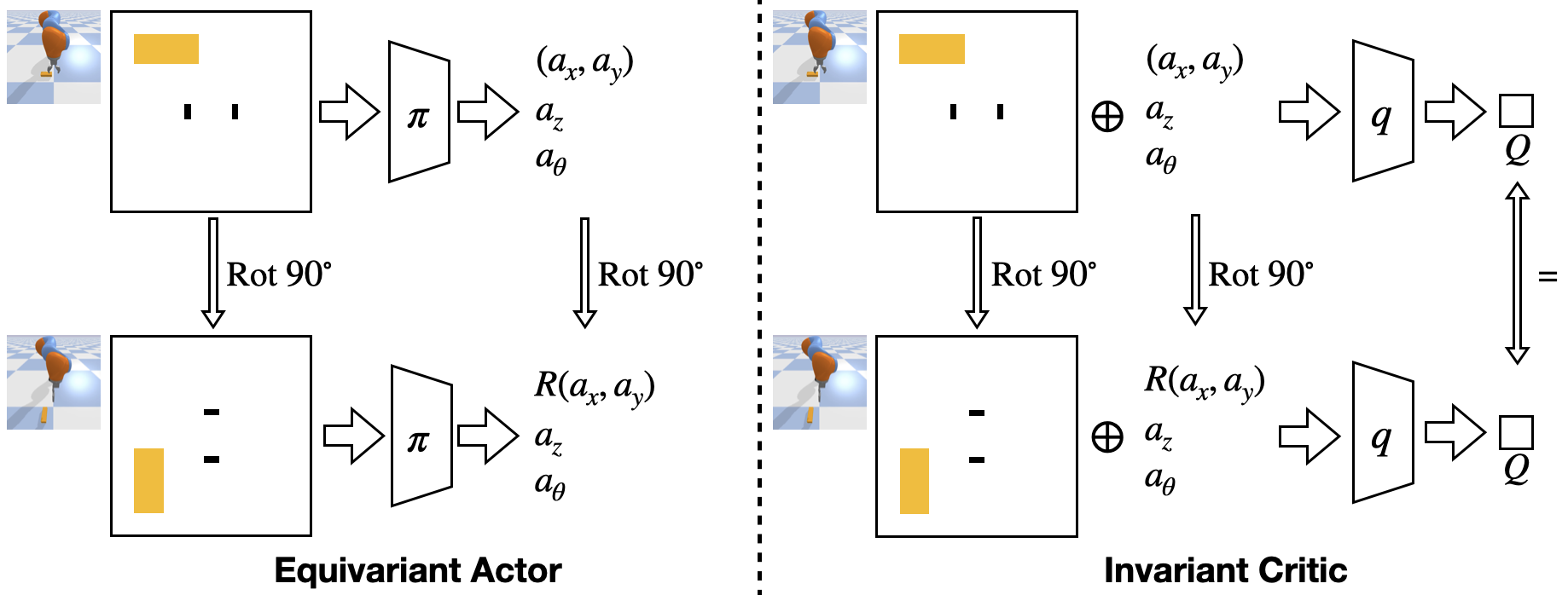
In Equivariant SAC, we hardcode the symmetries of the task in the structure of the actor and the critic to improve the sample efficiency. Specifically, if the input state of the actor (left) is rotated, the output action of the actor will be rotated by the same amount. If the input state and action of the critic (right) are rotated, the output Q-value of the critic will remain the same. Please see our prior work for a detailed description of the method.

Block Picking

Block Pushing
Clutter Grasping

Block in Bowl
The real-world experimental environments.

Our method is sample efficient enough to learn manipulation policies directly on a real-world system. Equivariant SAC only requires less than 1 hour to solve Block Picking, Clutter Grasping, and Block Pushing. In Block in Bowl, our method requires 2 hours and 40 minitues to converge.
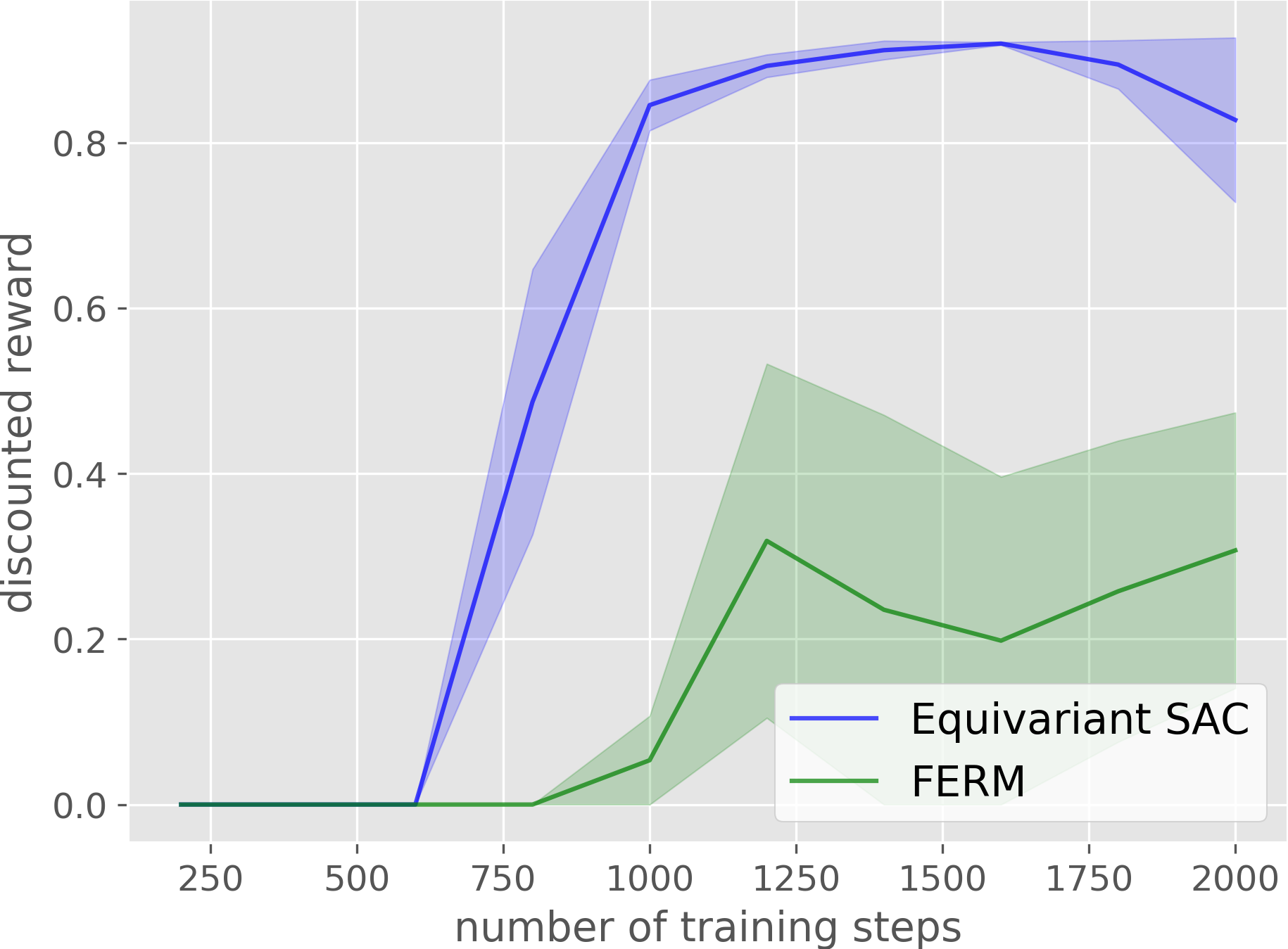
Block Picking
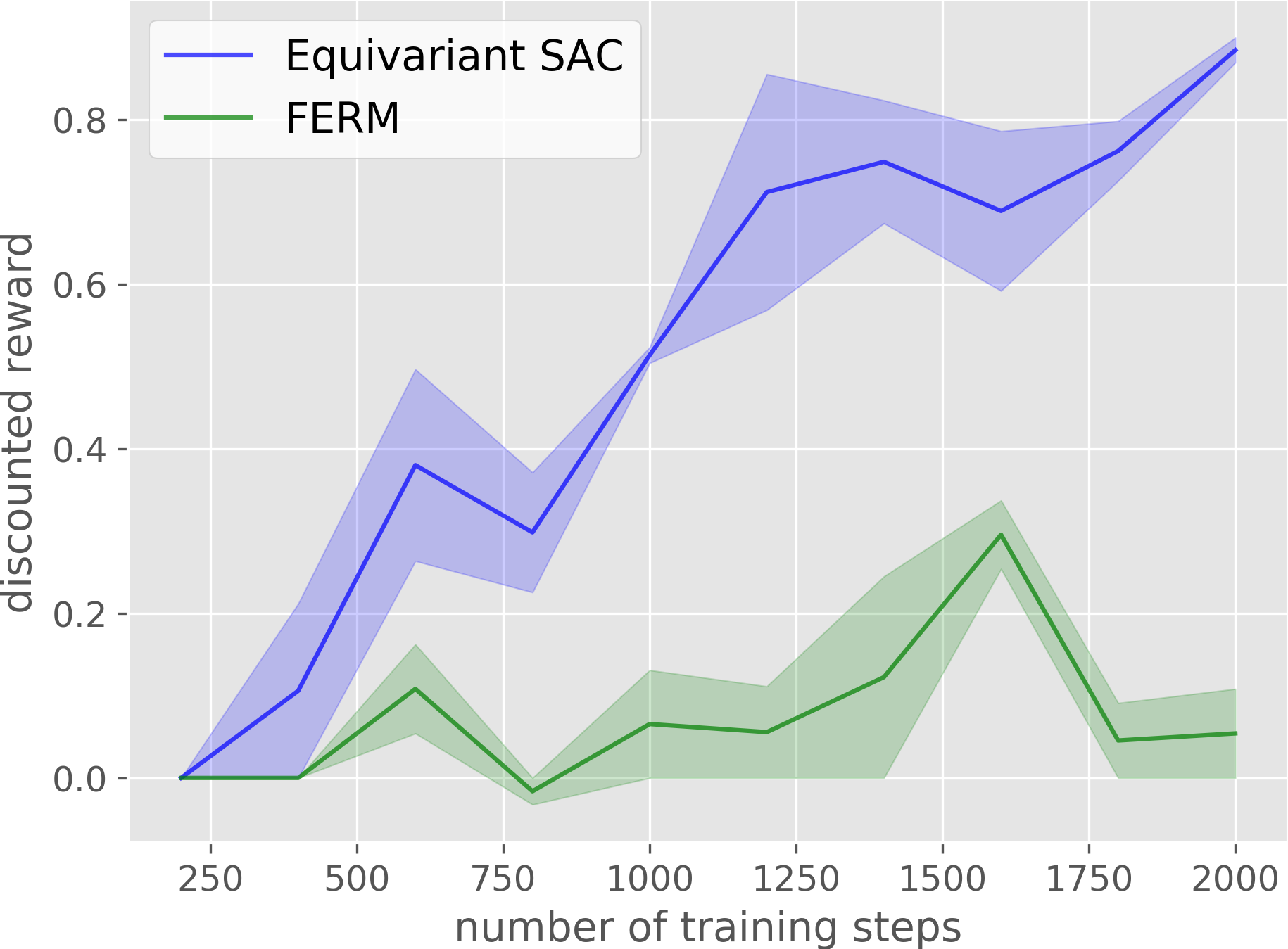
Block Pushing
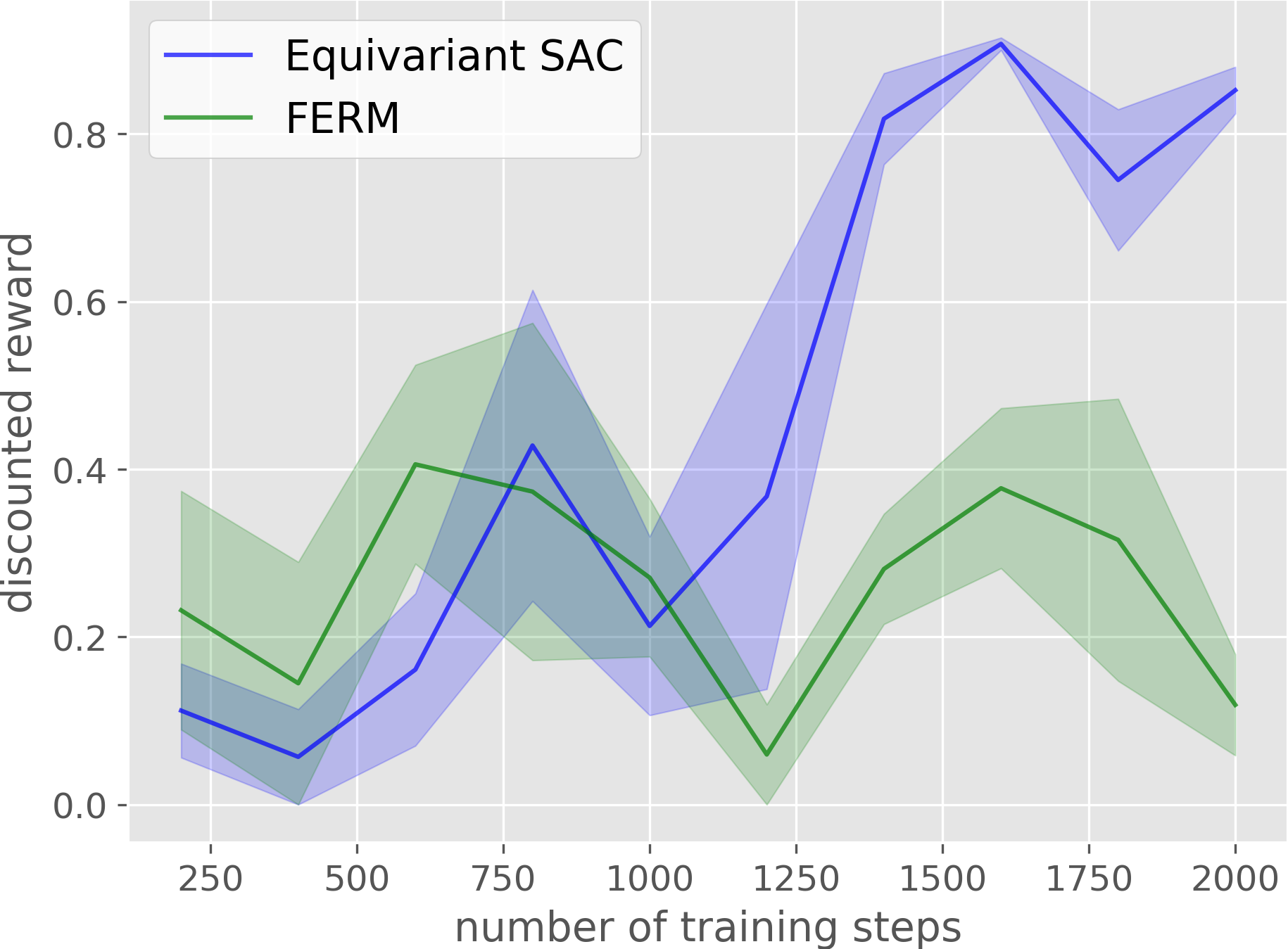
Clutter Grasping
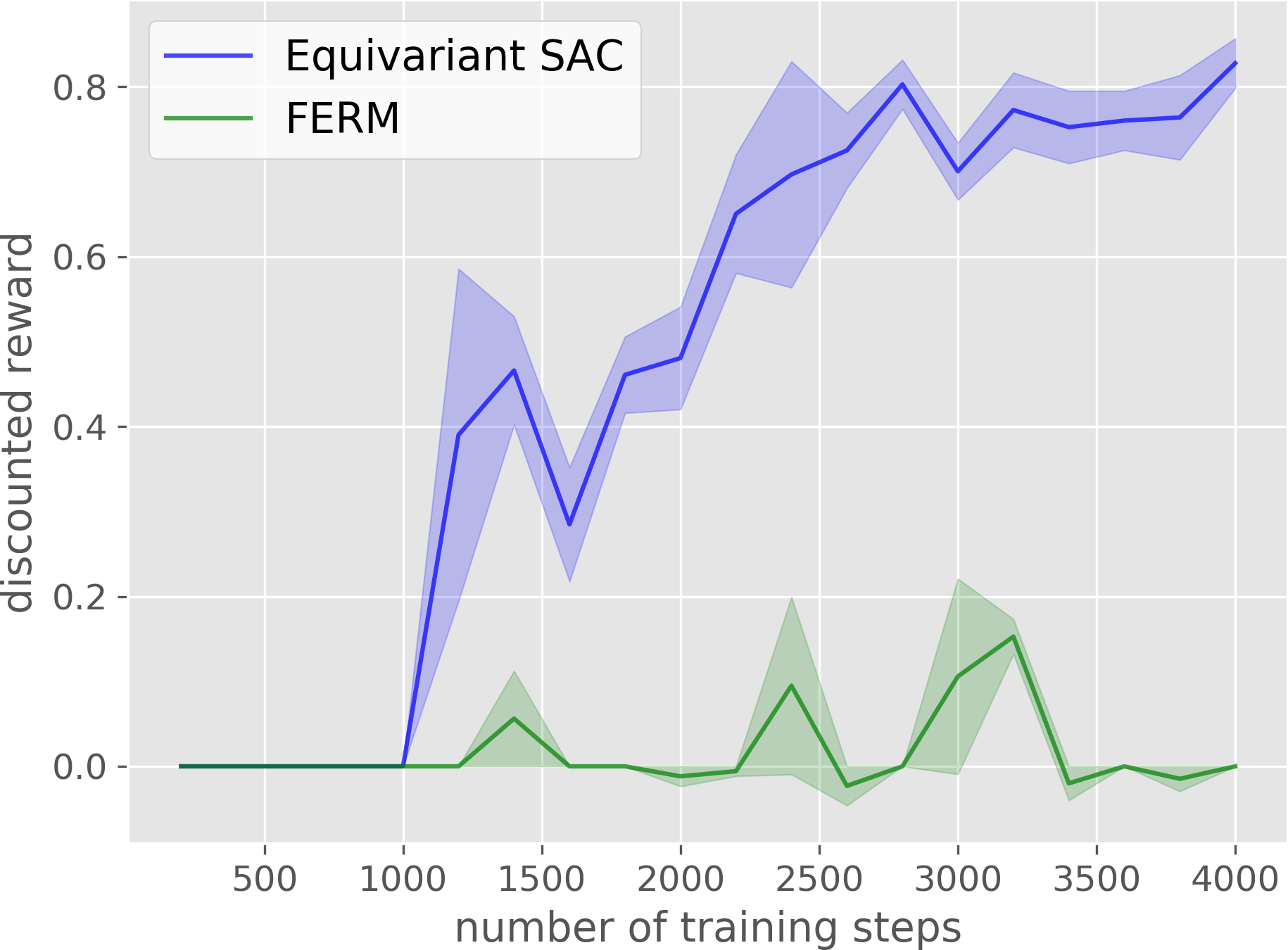
Block in Bowl
Compared with the baseline, our method has a much higher sample efficiency in on-robot learning.
Video
Spotlight Talk
Code
https://github.com/pointW/equi_rl
Citation
@inproceedings{
wang2022onrobot,
title={On-Robot Learning With Equivariant Models},
author={Dian Wang and Mingxi Jia and Xupeng Zhu and Robin Walters and Robert Platt},
booktitle={6th Annual Conference on Robot Learning},
year={2022},
url={https://openreview.net/forum?id=K8W6ObPZQyh}
}
Contact
If you have any questions, please feel free to contact Dian Wang at wang[dot]dian[at]northeastern[dot]edu.